
Jaz
@jaz.bsky.social
Yeah I first learned about this lil guy from this awesome video - www.youtube.com/watch?v=Gpsz...

Destroying a well known synth to build a Rhodes (reface CP)
Building a custom Rhodes inspired piano for my home studio from a Yamaha Reface CP. More about Munstre at http://munstre.com Links for each element in the b...
www.youtube.com
new friend for #synthsky
just came up for air after my initial goofing around an an hour passed without me noticing
it's really fun, has a really good Rhodes piano sound as well as a Wurlitzer that feels super genuine, definitely better w/ headphones and/or proper sidechain
Yamaha Reface-CP


i wanna hear someone use gigameters in some kind of important business setting, it would sound so sci-fi
i don't touch the PDS or the TypeScript codebases at all really, this is a @divy.zone or @dholms.xyz question...
(high mem usage on a single-user PDS)
lol, that reminds me of a classic @jacob.gold saying where, when one of us would talk about the amount of bytes this will end up consuming in a struct or on disk or something, Jake would always reply with "Don't worry, I'll pay for it" to get us back on track
Then when you've got 2-3 services that want to use this pattern, you can go through with the UID interning migration and deal with it then, where the payoff is going to be much more impactful and it will actually _reduce_ complexity across your architecture by making those services simpler.
And so in lieu of performing this huge optimization that may have hidden costs (i.e. latency/correctness), you can have the services that _need_ this functionality act as a boundary for it.
Have the optimization live in the service that needs it, keep the mapping there, save complexity elsewhere.
to be fair tho this kind of change would be pretty significant and require recreating most of our DB tables and rewriting all the URIs we have stored to use the UIDs...
but it isn't as hard as i.e. swapping our underlying database to one with a totally different architecture and schema
For instance, in Bsky's AppView architecture, we haven't interned DIDs as uints or anything like that.
It would definitely save us a _ton_ of bytes in our indices and in our DB tables but would add complexity (and a tiny bit of latency) and we aren't anywhere near capacity on the AppView databases.
But when it comes to choosing which DB you want to use for your system, thinking about how the DB will scale and making design decisions at the outset with an intended scaling path in mind is best practice.
Stuff that's really hard to change in the future should be optimized ahead of time i guess
The best example I can think of for this is i.e. hitting the DB to tell if a thing exists initially and then later on optimizing by throwing an in-memory bloom filter in front of it.
That's a thing you can usually add in later once your DB load becomes expensive or concerning.
I think there's a difference between prematurely optimizing things that will be easy to optimize in the future vs picking architectures and/or design patterns that will scale out horizontally or at least more reasonably as your system grows to "realistic" levels of load.
probably but they might also result in significantly more bottle caps getting recycled which could reduce the amount of plastic going to landfills maybe?
would be cool to see the stats on it tbh
The big dip was the public launch day when we removed invites and onboarded 850k people in 24 hours.
Lots of those users were new and sharing images and weren't used to using alt text.
We usually see 800k-1m posts per day but on the public launch day and after there were over 2m posts/day briefly.
Here's a bit of a a big one going back over the past 6 months of alt-text usage on the network.
Pre-launch we were floating around 24-25%, then on launch day we dropped down to 10% (lowest I've seen)
We bounced back after that and have slowly got back to 21-22% alt-text usage.

i think an error frame is only sent at the end of the stream and you need to reconnect after seeing one iirc
No but it's just running some open source network observation tools for AT Proto I built - github.com/bluesky-soci...
Making a Grafana public is a bit of a pain when it's running offline unfortunately. Might get around to it someday.

indigo/cmd/sonar at main · bluesky-social/indigo
Go source code for Bluesky's atproto services. Contribute to bluesky-social/indigo development by creating an account on GitHub.
github.comI've done a bit on my personal blog but I can only do longform writing between 10PM and 3AM Friday night/Saturday Morning at most twice a month

AppView error rate in the past hour has been 0.026%, you can collect your reward by going to your nearest outside and looking at the sky.
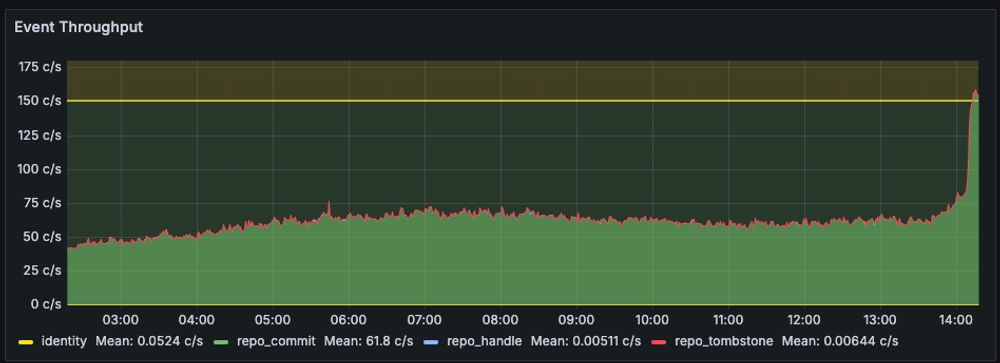
Slow comedown rolling along, still ~135 posts/likes/reposts per second coming through though, wonder if this will last a few hours.
My stats page will look interesting tomorrow...
Might adjust the default range so the spike is easier to see compared to a normal day.
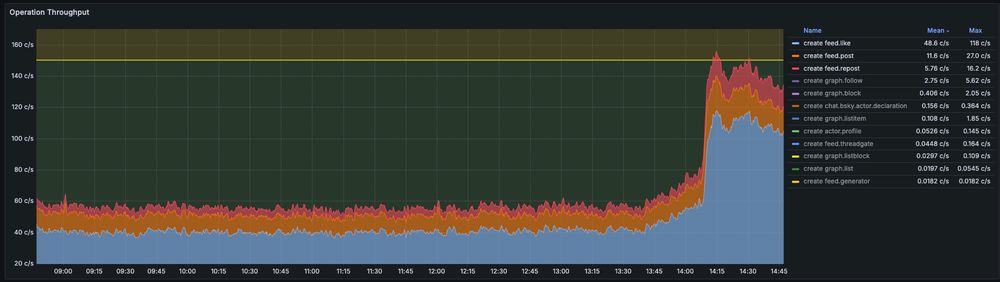

you can try but you'll have to go at least 3x this intense to get to the highest throughput we've ever seen (on public launch day in Japan, was sustained at >450 evt/sec for a full hour)
This one shows just likes, posts, and reposts being created, to give y'all a bit more context.

So uh, did something happen?
(Check out the Bluesky Firehose traffic , that's a >2x jump lmao)
might be a local bunny issue from the edges in your region, though their status page isn't saying anything about it :(
There are ~23 accounts with >100k followers and somewhere in the neighborhood of 200 posts/reposts from them collectively daily.
lasagna truly is the canister Damascus of pasta

someone make a coinstar for pasta where i can bring in my 1/8th filled boxes of various pastas and out comes a pan of lasagna
I watch Devolver Direct every once in a while but usually because it's a great show and the writing and acting are good
the celestial bodies must align so that we may align celestial bodies
(i vetoed the first version of that, sorry lol)
pride month should let enbies enter the astral plane to commune with others across vast distances
Things that I "have to use" every day for work are like, the actual tools of my trade which ends up being Slack, Notion, a terminal, code editor, and a browser/github.
Nothing else ends up in my daily necessity group. Even a really handy tool won't be there unless it solves an everyday problem well
I think most tech usage moves in "hype cycles" tbh, I can't remember the last piece of technology that became a "must have" daily.
when people remember a thing exists, they use it again but if it isn't "required" on a daily basis because it's so much better than life without it, usage is cyclical
I use Copilot in my editor a lot, it helps me get stuff done faster but probably also raises my tolerance for tedious and poorly-factored code because I don't have to write as much of it when the editor does it for me.
I still think it's a net productivity increase for me personally, for now.
Facebook spent hundreds of millions if not >$1bn on their Research SuperCluster (ai.meta.com/blog/ai-rsc/)
All the hardware outlined in that blog post is now out of date and not competitive with the hardware "bleeding-edge" models are trained on today
It's an incredibly expensive compute arms race
Introducing the AI Research SuperCluster — Meta’s cutting-edge AI supercomputer for AI research
Introducing the AI Research SuperCluster — Meta’s cutting-edge AI supercomputer for AI research
ai.meta.com
I don't think AI can be trusted by people who work in industries that require "correctness" and the only reason it works for software engineering is because if the code is wrong it will let you know eventually or you can write tests for it to catch it beforehand.
Engineers regularly produce bugs.
Once the companies realize that the current model architectures can't actually give you another leap at compute scales we're capable of in the next 3-5 years, they won't have any money or agility left to pivot and try new architectures or do anything creative.
All the innovation starts w/ research
The "best" companies in this first wave atm are burning literal Billions of dollars a year on training models for what is now proving to be incremental improvements ever since the gpt2->3 capability leap.
They're operating under the supposition that more compute and bigger models will leap again.